
Nguồn gốc của mạng neuron nhân tạo
Chúng ta đang muốn tạo ra một thuật toán có thể thông minh như con người, câu hỏi đặt ra là liệu có thể tận dụng những kiến thức về cách bộ não người hoạt động để tạo nên thuật toán như vậy hay không? Trước tiên hãy cùng tìm hiểu về bộ não - thứ tạo nên sự thông thái của giống loài tiến hóa bậc nhất hành tinh này, tất nhiên đây không phải là tiết sinh học, nên mình sẽ nói ngắn gọn thôi. Về cơ bản, bộ não của chúng ta được cấu tạo từ rất nhiều tế bào thần kinh (còn gọi là neuron thần kinh) kết nối với nhau. Thành phần cơ bản của một neuron gồm có sợi nhánh (Dendrite), nhân tế bào (Nucleus) và sợi trục (Axon).
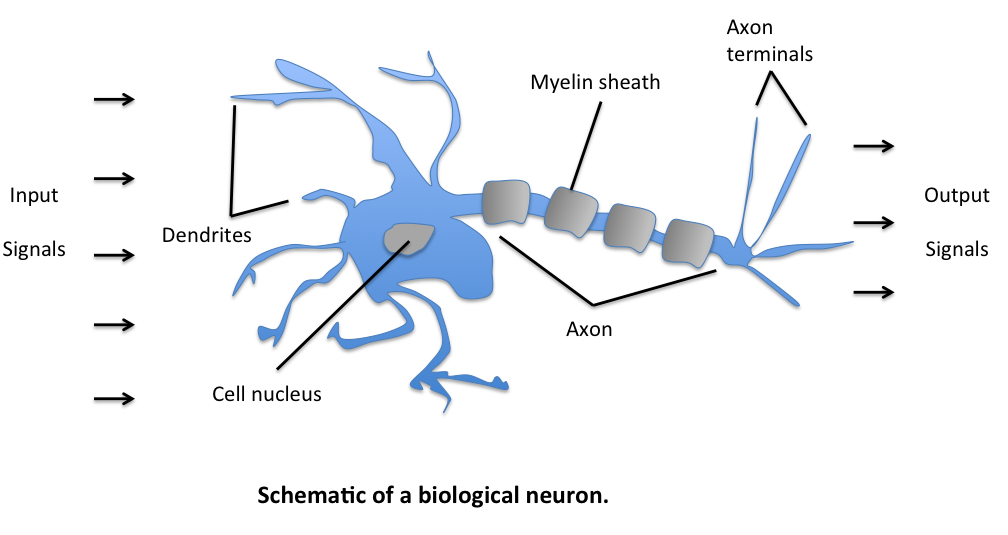 |
| Hình 1: Neuron thần kinh (Nguồn) |
Sợi nhánh đóng vai trò input các tín hiệu điện từ sợi trục của các neuron thần kinh khác. Sau đó, tín hiệu được gửi đến nhân tế bào để xử lý rồi gửi output thông qua sợi trục. Nghe có vẻ đơn giản, nhưng hàng tỷ neuron kết nối với nhau đã tạo nên bộ não kỳ diệu của con người, giúp chúng ta có khả năng suy nghĩ và thực hiện các tác vụ phức tạp.
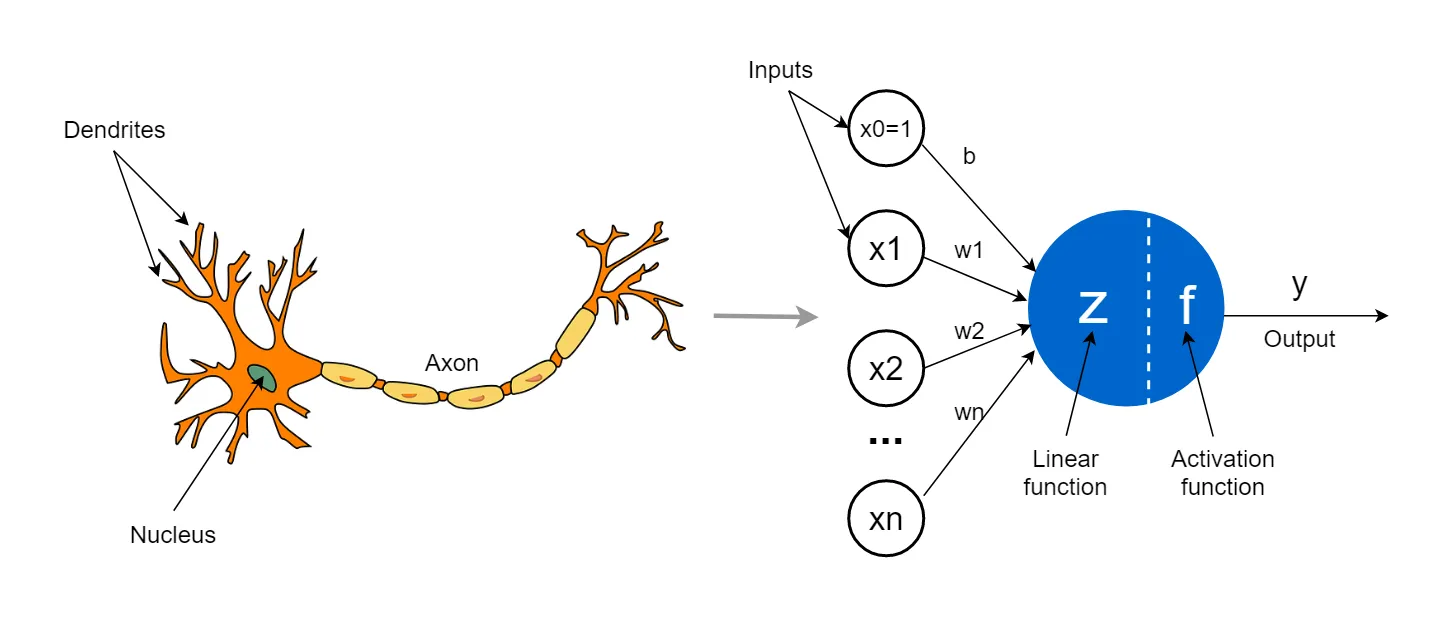
Vận dụng những hiểu biết đó, người ta đưa ra ý tưởng về một đơn vị neuron nhân tạo (artificial neuron unit).
 | |
|
Chúng ta có thể hiểu đơn vị neuron nhân tạo là phiên bản đơn giản hóa của một neuron thần kinh với input là một hoặc nhiều số thực. Các số này được truyền vào một hàm xử lý (ta sẽ nói rõ hơn hàm này ở phần sau), trả ra output là một số thực khác. Tương tự như mạng neuron sinh học, người ta kết hợp rất nhiều đơn vị neuron nhân tạo lại để tạo nên một mạng neuron nhân tạo (artificial neural network - ANN) với hy vọng có thể xử lý được các tác vụ phức tạp hay đưa ra những dự đoán chính xác từ dữ liệu đầu vào ban đầu.
- Hiểu biết của con người về cách bộ não hoạt động vẫn còn hạn chế. Hàng năm, có rất nhiều những khám phá mới trong ngành khoa học thần kinh.
- Việc cố gắng bắt chước một cách mù quáng những đặc điểm sinh học của não người có thể sẽ không tạo ra được "trí thông minh", nhất là với những hiểu biết hạn chế hiện tại.
- Vì vậy, ta không tập trung vào nguồn gốc ý tưởng từ sinh học lúc đầu mà chú trọng hơn vào việc xây dựng các nguyên tắc kỹ thuật, những nguyên lý thiết kế để tạo ra được một thuật toán hiệu quả. Điều này tương tự như trong việc phát minh ra máy bay. Ban đầu người ta lấy cảm hứng từ loài chim. Nhưng sau nhiều lần thất bại trong việc bắt chước y hệt các đặc điểm sinh học của chim, người ta đúc kết, vận dụng các nguyên tắc kỹ thuật của khí động lực học trong vật lý, cuối cùng tạo ra được chiếc máy bay có thể bay được hiệu quả.
- Mặc dù chỉ sử dụng những mô hình neuron cực kỳ đơn giản, ta vẫn có thể tạo ra được những thuật toán rất mạnh mẽ và được vận dụng hiệu quả trong nhiều lĩnh vực.
Trend deep learning
Những khái niệm về mạng neuron nhân tạo đã xuất hiện lần đầu từ những năm 60 của thế kỷ trước. Trải qua biết bao nhiêu thăng trầm, có những lúc không còn được ưa chuộng. Mãi cho đến khoảng năm 2005, mạng neuron nhân tạo tái sinh mạnh mẽ với tên gọi mới là Học sâu (Deep learning). Được nghiên cứu rộng rãi trong các lĩnh vực từ nhận diện giọng nói, thị giác máy tính đến xử lý ngôn ngữ tự nhiên. Vậy tại sao lại là lúc này? - Một câu hỏi phổ biến có thể bạn sẽ thắc mắc. Khi nói về trend Deep learning hiện nay, có lẽ biểu đồ dưới đây của giáo sư Andrew Ng sẽ có thể giải thích một cách ngắn gọn nhất.
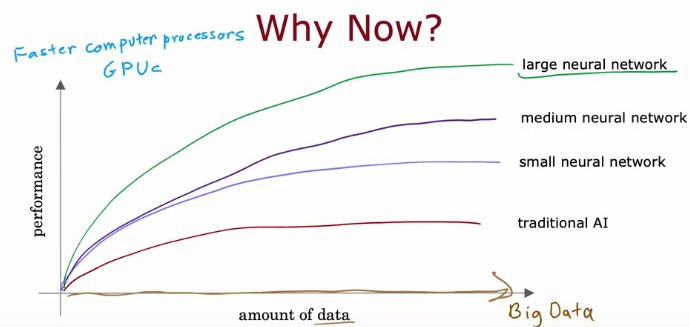 |
| Hình 3: Deep learning trend (Nguồn: ML spec course) |
Lý do đầu tiên phải kể đến chính là dữ liệu lớn (Big data). Trong hơn 1 thập kỷ vừa qua, với sự phát triển của Internet, điện thoại di động hay xu hướng số hóa, sự bùng nổ về lượng dữ liệu trong nhiều lĩnh vực ứng dụng là hệ quả tất yếu, thay thế cho các văn bản giấy truyền thống. Trong khi các phương pháp học máy truyền thống (nếu bạn đã tìm hiểu về linear hay logistic regression) dường như không tận dụng được lượng dữ liệu lớn được thêm vào, neural network, đặc biệt là các mạng lớn với rất nhiều đơn vị neuron nhân tạo, có thể cải thiện hiệu năng đáng kể khi dữ liệu ngày càng lớn. Việc xây dựng neural network tốn khá nhiều tài nguyên tính toán, vì vậy chúng ta có lý do thứ 2 làm nên trend về deep learning. Sự phát triển của những bộ vi xử lý mạnh mẽ, nhất là GPU (thiết kế ban đầu dành cho việc xử lý đồ họa, nhưng cũng rất hiệu quả trong việc xây dựng các thuật toán deep learning), đóng một vai trò then chốt cho sự thành công của deep learning.
Một số thuật ngữ:
- Mạng neuron nhân tạo (ANN) / mô hình neural network: gọi ngắn gọn là neural network.
- Đơn vị neuron nhân tạo (artificial neuron unit): gọi tắt là neuron / unit
Dài quá không đọc (tl;dr):
- Neural network chỉ lấy cảm hứng từ cách não người hoạt động chứ không bắt chước hoàn toàn.
- Một mô hình neural network bao gồm rất nhiều neurons, nhận input đầu vào là các con số, xử lý tính toán rồi cho ra kết quả dự đoán mong muốn.
- Khái niệm neural network đã xuất hiện từ rất lâu nhưng gần đây mới thật sự bùng nổ, nguyên nhân chính đến từ Big data và sức mạnh tính toán của thời nay.
Cách một mô hình neural network "suy luận"
- Đầu tiên, mô hình thực hiện tính tích của điểm thi với hệ số tương ứng, môn chuyên thì hệ số sẽ cao hơn (vì đang thi vào trường chuyên cơ mà), sau đó cộng các tích đó lại với nhau. Điều này tương đương với cách mà trường thực hiện tính điểm tổng cho một thí sinh. Ở đây, ta có một số thuật ngữ, các hệ số w1, w2, w3 được gọi là trọng số (weight), cách tính tổng như trên gọi là tổng trọng số (weighted sum).
- Tiếp đến, mô hình cộng kết quả trên với tham số b (gọi là bias). Giả sử, dựa vào điểm chuẩn của các năm trước, bạn nhận thấy rằng nếu một học sinh đạt có tổng điểm trên 25 điểm thì sẽ có trên 50% cơ hội đậu. Lúc này, chọn b = -25 có ý nghĩa rằng, nếu mô hình output ra con số lớn hơn 0 (tổng điểm - 25 > 0 ⇔ tổng điểm > 25) thì học sinh đó sẽ có trên 50% cơ hội đậu.
- Cuối cùng, chúng ta muốn kết quả của mô hình là một con số xác suất, tức là số thực từ 0 đến 1, thay vì là điểm tổng trừ đi bias như hiện tại. Khi này, ta cần sử dụng một công cụ toán học là hàm Sigmoid. Hàm sigmoid nhận vào input là một số thực và cho ra output là số thực trong khoảng (0; 1), cụ thể hơn nếu input là số dường thì hàm sigmoid cho ra output lớn hơn 0.5 và ngược lại. Ta tận dụng tính chất này và áp dụng vào mô hình để tính được xác suất đậu của học sinh. Ở đây, ta cũng có một số thuật ngữ, kết quả output của mô hình này được gọi là activation, và hàm sigmoid là một activation function. Có rất nhiều activation function khác nhau, sigmoid chỉ là một trong số đó.
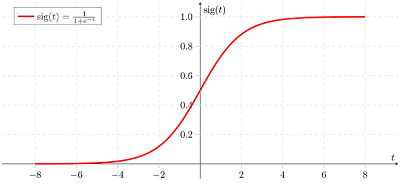 |
| Hình 4: Hàm sigmoid (Nguồn: Medium) |

Hình 5: Một neuron / unit
Ta có thể dùng nhiều neuron liên kết lại với nhau để xây dựng nên một neural network. Liên kết ở đây nghĩa là input của neuron này là output của các neuron khác, các input được neuron xử lý để đưa ra output, để rồi đến lượt kết quả output này lại làm input cho một neuron khác nữa. Mỗi neuron sẽ có trọng số (weights) và bias khác nhau.
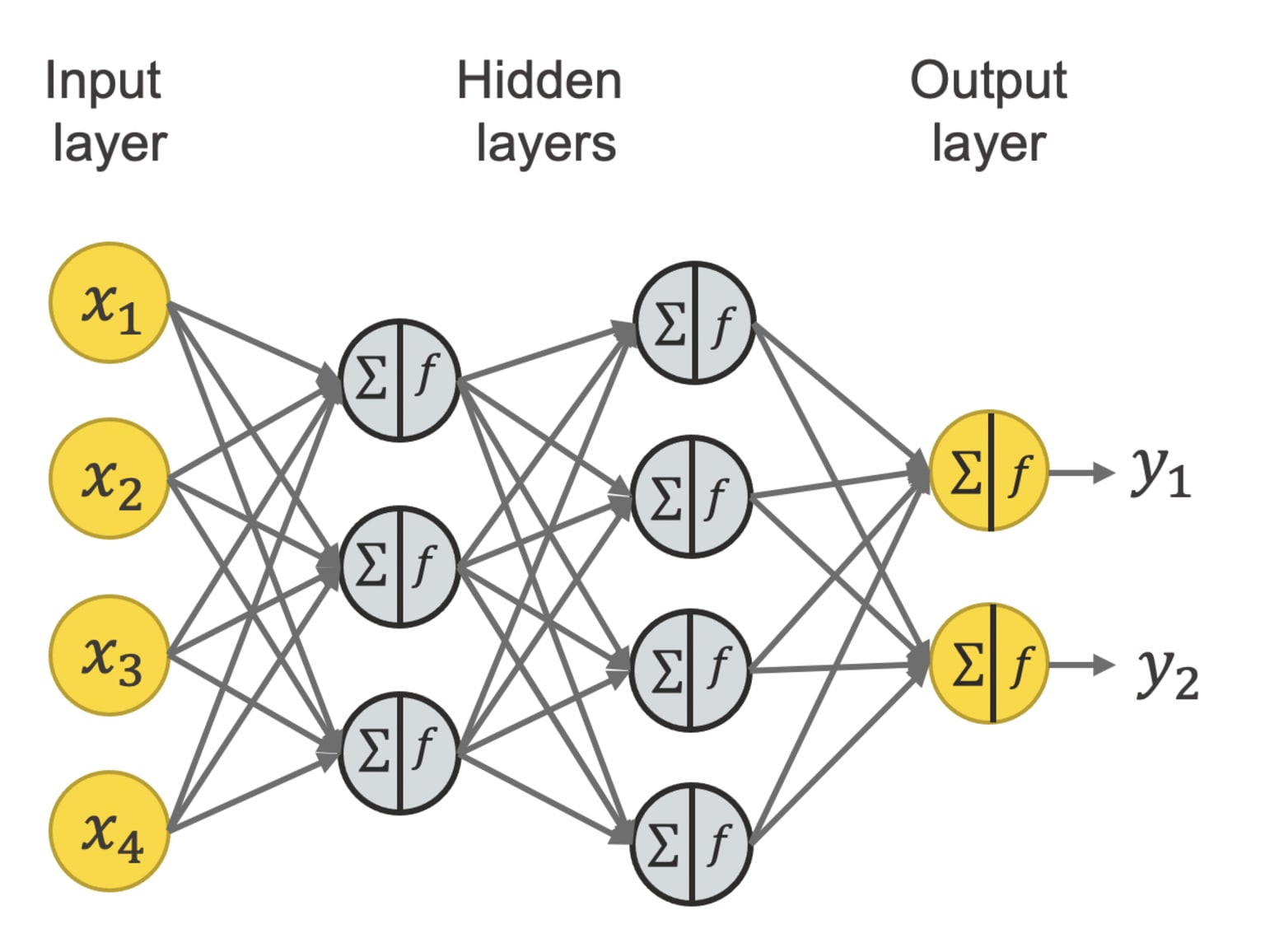
Hình 6: Neural network(Nguồn)
Một số khái niệm / thuật ngữ:- Layer: tập hợp các neuron nhận các input giống nhau từ layer trước và cùng output ra các con số truyền vào input của layer tiếp theo. Một layer được minh họa là các neuron nằm trên cùng một cột. Có các loại layer sau:
- Input layer: có thể hiểu là một list các con số input của model
- Output layer: layer nằm cuối cùng, xuất ra kết quả của model
- Hidden layers: các layer nằm giữa input và output layer
- Một neural network bắt buộc phải có 1 input layer và 1 output layer, có thể có 0, 1 hoặc nhiều hidden layer. Khi nói đến số lượng layer của neural network, người ta không tính input layer, như hình trên minh họa một neural network với 3 layer. Những mô hình có nhiều layer, tạo nên một mạng neuron “sâu” là lý do xuất hiện thuật ngữ học sâu (Deep learning).
- Loại layer trong đó mỗi neuron được nối với tất cả các neuron ở layer trước được gọi là Dense layer (hay fully-connected layer), ngoài ra còn có các loại layer khác nhưng trong bài này, ta chỉ nói về dense layer.
Bây giờ, ta thử giải quyết bài toán nhận diện chữ số viết tay. Input đầu vào là một tấm ảnh trắng đen (kích thước 28x28 pixel) về chữ số viết tay, kèm theo nhãn (label), tức giá trị chữ số trong ảnh. Tấm ảnh này có thể biểu diễn dưới dạng một ma trận 2 chiều kích thước 28 dòng 28 cột, với giá trị của mỗi pixel từ 0 (màu đen) đến 1 (màu trắng). Output của bài toán sẽ là một con số (từ 0-9) phản ánh đúng chữ số viết tay thể hiện trong ảnh.
 |
| Hình 5: Một neuron / unit |
|
| Hình 6: Neural network(Nguồn) |
- Layer: tập hợp các neuron nhận các input giống nhau từ layer trước và cùng output ra các con số truyền vào input của layer tiếp theo. Một layer được minh họa là các neuron nằm trên cùng một cột. Có các loại layer sau:
- Input layer: có thể hiểu là một list các con số input của model
- Output layer: layer nằm cuối cùng, xuất ra kết quả của model
- Hidden layers: các layer nằm giữa input và output layer
- Một neural network bắt buộc phải có 1 input layer và 1 output layer, có thể có 0, 1 hoặc nhiều hidden layer. Khi nói đến số lượng layer của neural network, người ta không tính input layer, như hình trên minh họa một neural network với 3 layer. Những mô hình có nhiều layer, tạo nên một mạng neuron “sâu” là lý do xuất hiện thuật ngữ học sâu (Deep learning).
- Loại layer trong đó mỗi neuron được nối với tất cả các neuron ở layer trước được gọi là Dense layer (hay fully-connected layer), ngoài ra còn có các loại layer khác nhưng trong bài này, ta chỉ nói về dense layer.
 |
| Hình 7: Ma trận pixel (Nguồn: 3Blue1Brown) |
Ta tiến hành xây dựng một mô hình neural network để giải quyết bài toán này. Khi xây dựng mô hình, việc lựa chọn số hidden layer và số unit mỗi layer sẽ tạo nên kiến trúc của mô hình (neural network architecture), và có thể ảnh hưởng đến độ hiệu quả của nó. Mô hình dưới đây chỉ là một trong rất nhiều kiến trúc mô hình có thể lựa chọn. Sau khi làm phẳng ma trận ảnh 2 chiều (nối đuôi từng hàng với nhau), được một dãy gồm 784 số, ta đưa tấm ảnh đó vào mô hình neural network như sau:
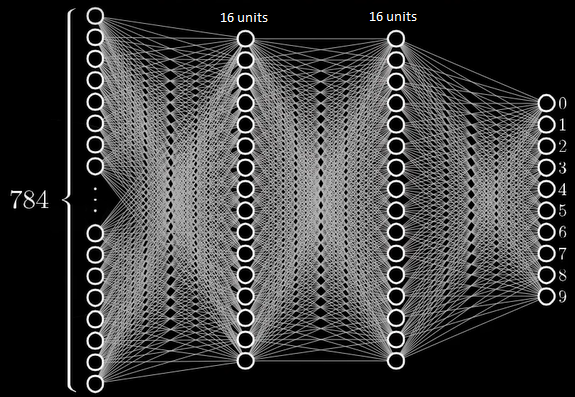 |
Hình 8: Mô hình dự đoán chữ viết tay (Nguồn: 3Blue1Brown) |
Quay trở lại bài toán, với những trọng số, bias đã được học, cùng với một tấm ảnh 28x28 đầu vào, mô hình sẽ thực hiện “suy luận”, tức là tính toán trong từng unit lần lượt từng layer từ trái sang phải, layer sau tính toán dựa trên kết quả của layer trước. Quá trình này được gọi là lan truyền xuôi (forward propagation). 10 unit ở output layer sẽ ứng với 10 con số dự đoán. Sau khi mô hình thực hiện tính toán dựa trên ảnh đầu vào, ví dụ unit ứng với số 8 có giá trị lớn nhất (gần với 1 nhất) thì đó chính là kết quả dự đoán của mô hình. Các bạn có thể vào trang sau, để trải nghiệm tự mình viết số và để mô hình dự đoán
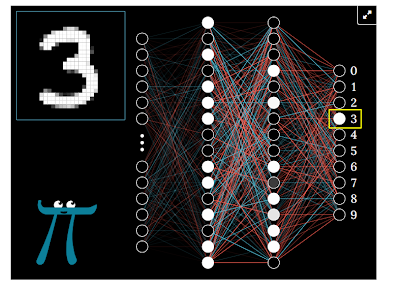
Hình 9: Chương trình mô phỏng quá trình dự đoán trên trang 3Blue1Brown
Một số thuật ngữ:
- Weighted sum là phép tính tổng của các tích
- Weight, bias là những tham số giúp các neuron unit thực hiện tính toán
- Activation là output của một neuron, thường được tính thông qua activation function
- Layer - Input layer - Hidden layer - Output layer
- Dense layer (fully-connected layer)
- Forward propagation
Dài quá không đọc (tl;dr):
- Quá trình tính toán của một neuron sẽ bao gồm 2 bước: tính weighted sum giữa input và các trọng số cộng cho bias; sau đó đưa kết quả tính được vào một activation function để có được output của neuron
- Quá trình tính toán của một model neural network sẽ bao gồm quá trình tính toán của tất cả các neuron có trong model, lần lượt theo từng layer. Input của neuron ở layer sau chính là output của layer trước (output của từng neuron ở layer trước).
Chính đặc điểm “tự học” là điều khiến mô hình neural network trở nên mạnh mẽ, trở thành nền móng của deep learning và được áp dụng trong rất nhiều các lĩnh vực khác nhau. Điều gì đáng sợ hơn một người có khả năng tự học? - Đó chính là một chiếc máy tính có khả năng tự học😀. Để hiểu rõ hơn về cách mà mô hình neuron network có thể học được, hãy cùng chờ đón những blog sau của mình nhé !
|
| Hình 9: Chương trình mô phỏng quá trình dự đoán trên trang 3Blue1Brown |
Một số thuật ngữ:
- Weighted sum là phép tính tổng của các tích
- Weight, bias là những tham số giúp các neuron unit thực hiện tính toán
- Activation là output của một neuron, thường được tính thông qua activation function
- Layer - Input layer - Hidden layer - Output layer
- Dense layer (fully-connected layer)
- Forward propagation
Dài quá không đọc (tl;dr):
- Quá trình tính toán của một neuron sẽ bao gồm 2 bước: tính weighted sum giữa input và các trọng số cộng cho bias; sau đó đưa kết quả tính được vào một activation function để có được output của neuron
- Quá trình tính toán của một model neural network sẽ bao gồm quá trình tính toán của tất cả các neuron có trong model, lần lượt theo từng layer. Input của neuron ở layer sau chính là output của layer trước (output của từng neuron ở layer trước).
Chính đặc điểm “tự học” là điều khiến mô hình neural network trở nên mạnh mẽ, trở thành nền móng của deep learning và được áp dụng trong rất nhiều các lĩnh vực khác nhau. Điều gì đáng sợ hơn một người có khả năng tự học? - Đó chính là một chiếc máy tính có khả năng tự học😀. Để hiểu rõ hơn về cách mà mô hình neuron network có thể học được, hãy cùng chờ đón những blog sau của mình nhé !
